

Sequence of shopping carts in-depth analysis with R
Author

published
Although the sankey diagram from the previous post provided us with a very descriptive tool, we can consider it a rather exploratory analisys. As I mentioned, sequence mining can give us the opportunity to recommend this or that product based on previous purchases, but we should find the right moment and patterns in purchasing behavior.
Therefore, the sankey diagram is not enough as it doesn’t show the duration between purchases. The other challenge is to understand that the customer has left us or just hasn’t made his/her next purchase yet. Therefore, in this post you will find technics which can help you to find patterns in customer’s behavior and churn based on purchase sequence. And you will find several interesting visualizations.
I will use an amazing R package – TraMineR. It allows us to extract all (or even more) data that we need. I highly recommend that you read this package manual because I won’t cover all features it has.
After we load the necessary libraries with the following code,
library(dplyr)
library(TraMineR)
library(reshape2)
library(googleVis)
we will simulate a sample of the data set. Suppose we sell 3 products (or product categories), A, B and C, and the client can purchase any combinations of products. Also, we know the date of purchase and the customer’s gender. Let’s do this with the following code:
# creating an example of shopping carts
set.seed(10)
data <- data.frame(orderId=sample(c(1:1000), 5000, replace=TRUE),
product=sample(c('NULL','a','b','c'), 5000, replace=TRUE,
prob=c(0.15, 0.65, 0.3, 0.15)))
order <- data.frame(orderId=c(1:1000),
clientId=sample(c(1:300), 1000, replace=TRUE))
sex <- data.frame(clientId=c(1:300),
sex=sample(c('male', 'female'), 300, replace=TRUE, prob=c(0.40, 0.60)))
date <- data.frame(orderId=c(1:1000),
orderdate=sample((1:90), 1000, replace=TRUE))
orders <- merge(data, order, by='orderId')
orders <- merge(orders, sex, by='clientId')
orders <- merge(orders, date, by='orderId')
orders <- orders[orders$product!='NULL', ]
orders$orderdate <- as.Date(orders$orderdate, origin="2012-01-01")
rm(data, date, order, sex)
Let’s take a look at the data frame we obtained. It looks similar to reality (head(orders) function):
## orderId clientId product sex orderdate ## 1 1 254 a female 2012-03-25 ## 2 1 254 b female 2012-03-25 ## 3 1 254 c female 2012-03-25 ## 4 1 254 b female 2012-03-25 ## 5 2 151 a female 2012-01-28 ## 6 2 151 b female 2012-01-28
Next, we will combine the products of each order to the cart. It is possible that the customer made two or more purchases on the same date. For instance, the client purchased product A on 2012-01-01 at 10:00 and products B and C on 2012-01-01 at 10:02. To me, this is the same shopping cart/order (A, B, C) which was split because of some reason but probably these two carts were created during the same session/visit. It is really easy to combine products with the following code:
# combining products to the cart
df <- orders %>%
arrange(product) %>%
select(-orderId) %>%
unique() %>%
group_by(clientId, sex, orderdate) %>%
summarise(cart=paste(product,collapse=";")) %>%
ungroup()
Finally, we have a df data frame which looks like (head(df) function):
## clientId sex orderdate cart ## 1 1 male 2012-01-22 a ## 2 1 male 2012-02-14 a ## 3 1 male 2012-03-08 a;b ## 4 1 male 2012-03-14 a;b ## 5 2 female 2012-02-11 a;c ## 6 2 female 2012-03-08 a;b
After this, we are ready to process carts/orders into the required format. And there will be some important clauses I want you to pay attention to:
- Firstly, each cart/order can be represented as a state or event. For example, sequence (A;B) -> (B) is a sequence of events, but in case we use durations (A;B)/10 -> (B)/5 (where 10 and 5 are days), it is a sequence of states. It means that the customer bought the (A;B) cart, since 10 days bought the (B) cart, since 5 days bought the next cart. As the time lapse is very important for our analysis, we should add the end date for each cart/order. The algorithm is the following: the end date of the cart/order is the date of the next cart from this client minus 1 day. For example, our client #1 bougth the (A) cart on 2012-01-22 and the (A) cart on 2012-02-14. Therefore, the end date for the first (A) cart is 2012-02-13 (2012-02-14 minus 1 day). The (A;B) cart of 2012-03-14 is the last one for this customer, hence the end date is the end of the period from which we extracted data plus 1 day (I will use the max() function for finding the end day of the reporting period).
- Secondly, suppose we extracted data on 2014-01-01. That means the end date for the cart (A;B) of client #1 is 2014-01-02. Therefore, the (A;B) state duration is from 2012-03-14 to 2014-01-02. To me, this means that the client has left us, because he hasn’t bougth anything for about the last two years. It can be very useful to identify such states. My idea is the following: we will create a dummy cart ‘nopurch’ for clients who haven’t purchased for defined period. In order to create these conditions I can suggest several solutions:
a) client hasn’t purchased for the last X days/months/years,
b) client hasn’t purchased for X days/months/years from the last purchase,
c) client hasn’t purchased for defined period from the last purchase.
I will share a combination of b) and c) approaches. For instance, we assume that our usual client should purchase once per month (30 days) and we will use this parameter for clients who purchased once. Also, we will take into account the customer’s purchasing habits. We will calculate the average time lapse between the customer’s purchases and define a critical period as the average time lapse multiplied for 1.5 times for clients who make a purchase more than once.
This approach allows us to identify broken sequences and either can be helpful to find patterns of the customer’s churn or won’t lead us to count the states of carts/orders that have an improbable duration.
We will use a loop for extracting each client from the data set, will calculate the average time lapse between purchases (with a 1.5 coefficient) or 30 days for one-time-buyers and will add both ‘nopurch’ dummies and the end date for each cart (state) with the following code:
max.date <- max(df$orderdate)+1
ids <- unique(df$clientId)
df.new <- data.frame()
for (i in 1:length(ids)) {
df.cache <- df %>%
filter(clientId==ids[i])
ifelse(nrow(df.cache)==1,
av.dur <- 30,
av.dur <- round(((max(df.cache$orderdate) - min(df.cache$orderdate))/(nrow(df.cache)-1))*1.5, 0))
df.cache <- rbind(df.cache, data.frame(clientId=df.cache$clientId[nrow(df.cache)], sex=df.cache$sex[nrow(df.cache)], orderdate=max(df.cache$orderdate)+av.dur, cart='nopurch'))
ifelse(max(df.cache$orderdate) > max.date, df.cache$orderdate[which.max(df.cache$orderdate)] <- max.date, NA)
df.cache$to <- c(df.cache$orderdate[2:nrow(df.cache)]-1, max.date)
# order# for Sankey diagram
df.cache <- df.cache %>%
mutate(ord = paste('ord', c(1:nrow(df.cache)), sep=''))
df.new <- rbind(df.new, df.cache)
}
# filtering dummies
df.new <- df.new %>%
filter(cart!='nopurch' | to != orderdate)
rm(orders, df, df.cache, i, ids, max.date, av.dur)
Let’s take a look for the first 4 clients (head(df.new, n=16) function):
## clientId sex orderdate cart to ord ## 1 1 male 2012-01-22 a 2012-02-13 ord1 ## 2 1 male 2012-02-14 a 2012-03-07 ord2 ## 3 1 male 2012-03-08 a;b 2012-03-13 ord3 ## 4 1 male 2012-03-14 a;b 2012-03-31 ord4 ## 5 2 female 2012-02-11 a;c 2012-03-07 ord1 ## 6 2 female 2012-03-08 a;b 2012-03-10 ord2 ## 7 2 female 2012-03-11 a;b 2012-03-31 ord3 ## 8 3 female 2012-01-17 a;c 2012-02-05 ord1 ## 9 3 female 2012-02-06 a;b;c 2012-03-03 ord2 ## 10 3 female 2012-03-04 a;b 2012-03-23 ord3 ## 11 3 female 2012-03-24 a;c 2012-03-31 ord4 ## 12 4 female 2012-01-05 a;c 2012-01-31 ord1 ## 13 4 female 2012-02-01 a;c 2012-02-11 ord2 ## 14 4 female 2012-02-12 a 2012-02-24 ord3 ## 15 4 female 2012-02-25 a;b 2012-03-21 ord4 ## 16 4 female 2012-03-22 nopurch 2012-04-01 ord5
The calculation for client #1 is the following:
2012-03-14 – 2012-01-22 = 52 days / 3 periods = 17 days * 1.5 = 26 days. So, the average duration is 26 days and he is still our client because the duration from 2012-03-14 to our reporting date (2012-04-01) is 18 days.
You can see ‘nopurch’ cart in client’s #4 sequence because:
2012-02-25 – 2012-01-05 = 51 days / 3 periods = 17 days * 1.5 = 26 days. So, average duration is 26 days and she is not our client because the duration from 2012-02-25 to our reporting date (2012-04-01) is 36 days (longer than 26 days).
Let create a sankey diagram with the data we have:
##### Sankey diagram #######
df.sankey <- df.new %>%
select(clientId, cart, ord)
df.sankey <- dcast(df.sankey, clientId ~ ord, value.var='cart', fun.aggregate = NULL)
df.sankey[is.na(df.sankey)] <- 'unknown'
# chosing a length of sequence
df.sankey <- df.sankey %>%
select(ord1, ord2, ord3, ord4)
# replacing NAs after 'nopurch' for 'nopurch'
df.sankey[df.sankey[, 2]=='nopurch', 3] <- 'nopurch'
df.sankey[df.sankey[, 3]=='nopurch', 4] <- 'nopurch'
df.sankey.plot <- data.frame()
for (i in 2:ncol(df.sankey)) {
df.sankey.cache <- df.sankey %>%
group_by(df.sankey[ , i-1], df.sankey[ , i]) %>%
summarise(n=n()) %>%
ungroup()
colnames(df.sankey.cache)[1:2] <- c('from', 'to')
# adding tags to carts
df.sankey.cache$from <- paste(df.sankey.cache$from, '(', i-1, ')', sep='')
df.sankey.cache$to <- paste(df.sankey.cache$to, '(', i, ')', sep='')
df.sankey.plot <- rbind(df.sankey.plot, df.sankey.cache)
}
plot(gvisSankey(df.sankey.plot, from='from', to='to', weight='n',
options=list(height=900, width=1800, sankey="{link:{color:{fill:'lightblue'}}}")))
rm(df.sankey, df.sankey.cache, df.sankey.plot, i)
Now we can see both broken sequences (‘nopurch’ variable) and ‘unknown’ states. This means that we defined customers as ‘alive’ but they didn’t make their next purchases as of the reporting date:
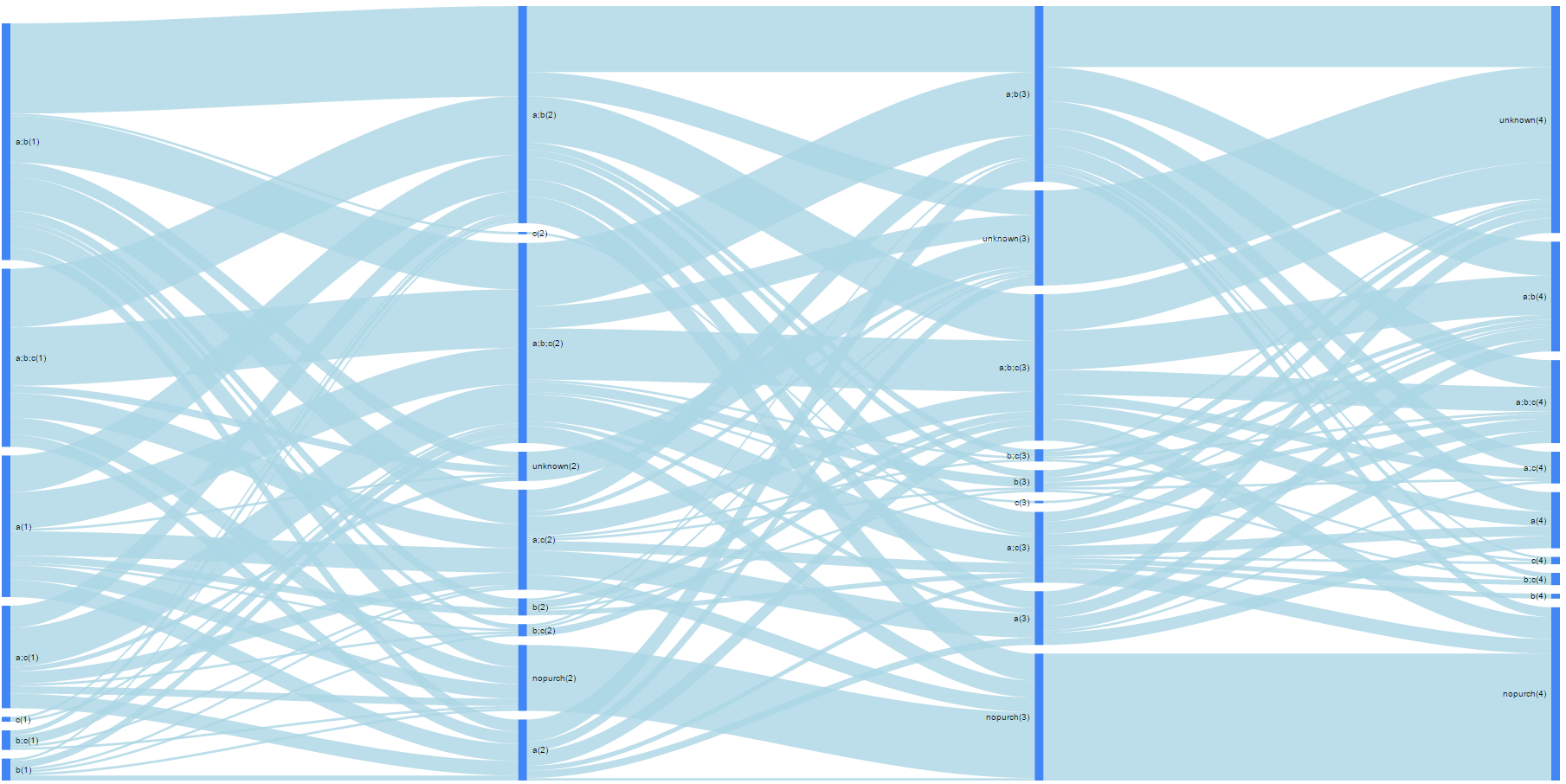
Ok, we can start an in-depth analysis. Because TraMineR doesn’t work with the dates format, we will convert dates to numbers. Also, we will change unclear dates (e.g. 14636, 14684, etc.) to the much clearer 1, 2, 3 and so on with the following code:
df.new <- df.new %>%
# chosing a length of sequence
filter(ord %in% c('ord1', 'ord2', 'ord3', 'ord4')) %>%
select(-ord)
# converting dates to numbers
min.date <- as.Date(min(df.new$orderdate), format="%Y-%m-%d")
df.new$orderdate <- as.numeric(df.new$orderdate-min.date+1)
df.new$to <- as.numeric(df.new$to-min.date+1)
From this point on, we will start to work on our main goal. First of all, we need to create a variable in the TraMineR format. The data frame we created is in SPELL format. Since TraMineR’s default format is STS, we will create a new STS variable (df.form) with the following code:
df.form <- seqformat(as.data.frame(df.new), id='clientId', begin='orderdate', end='to', status='cart',
from='SPELL', to='STS', process=FALSE)
Furthermore, we will create the TraMiner’s object and see the summary with the following code:
df.seq <- seqdef(df.form, left='DEL', right='unknown', xtstep=10) # xtstep - step between ticks (days)
summary(df.seq)
Note: I used left=’DEL’ parameter in order to remove NAs. The reason to the occurrence of NAs is, for example, that our min date in the data set was 2012-01-01 which was converted to y1 value. If the customer’s first purchase was on 2012-01-02 or y2, the algorithm generates an NA for y1. In this case the left=’DEL’ parameter moves the whole sequence one step back (from y2 to y1). Therefore, all of our sequences start from the y1 day. This way, we switched from calendar dates to sequence dates. The other parameters right=’unknown’ and void=’unknown’ mean that we replaced NAs and void elements at the end of the sequences for ‘unknown’. This is helpful for customers who are ‘alive’ but didn’t make their next purchase as of the reporting date.
Also, we will use the client’s gender as a feature in the analysis. Therefore, we will create a feature with the following code:
df.feat <- unique(df.new[ , c('clientId', 'sex')])
We will start with a distribution analysis which shows the state distribution at each time point (the columns of the sequence object) and plot two charts:
# distribution analysis
seqdplot(df.seq, border=NA, withlegend='right')
seqdplot(df.seq, border=NA, group=df.feat$sex) # distribution based on gender
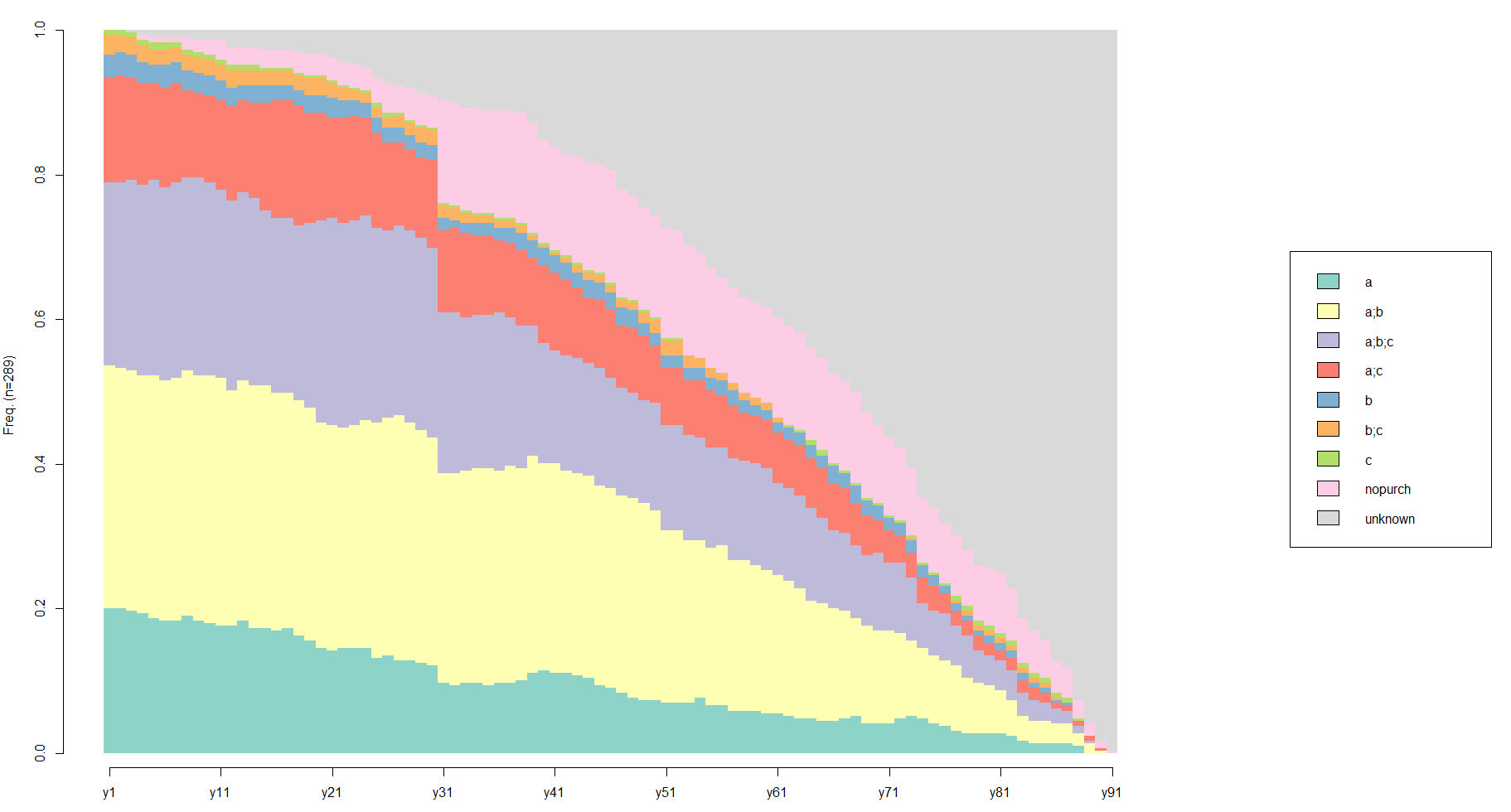
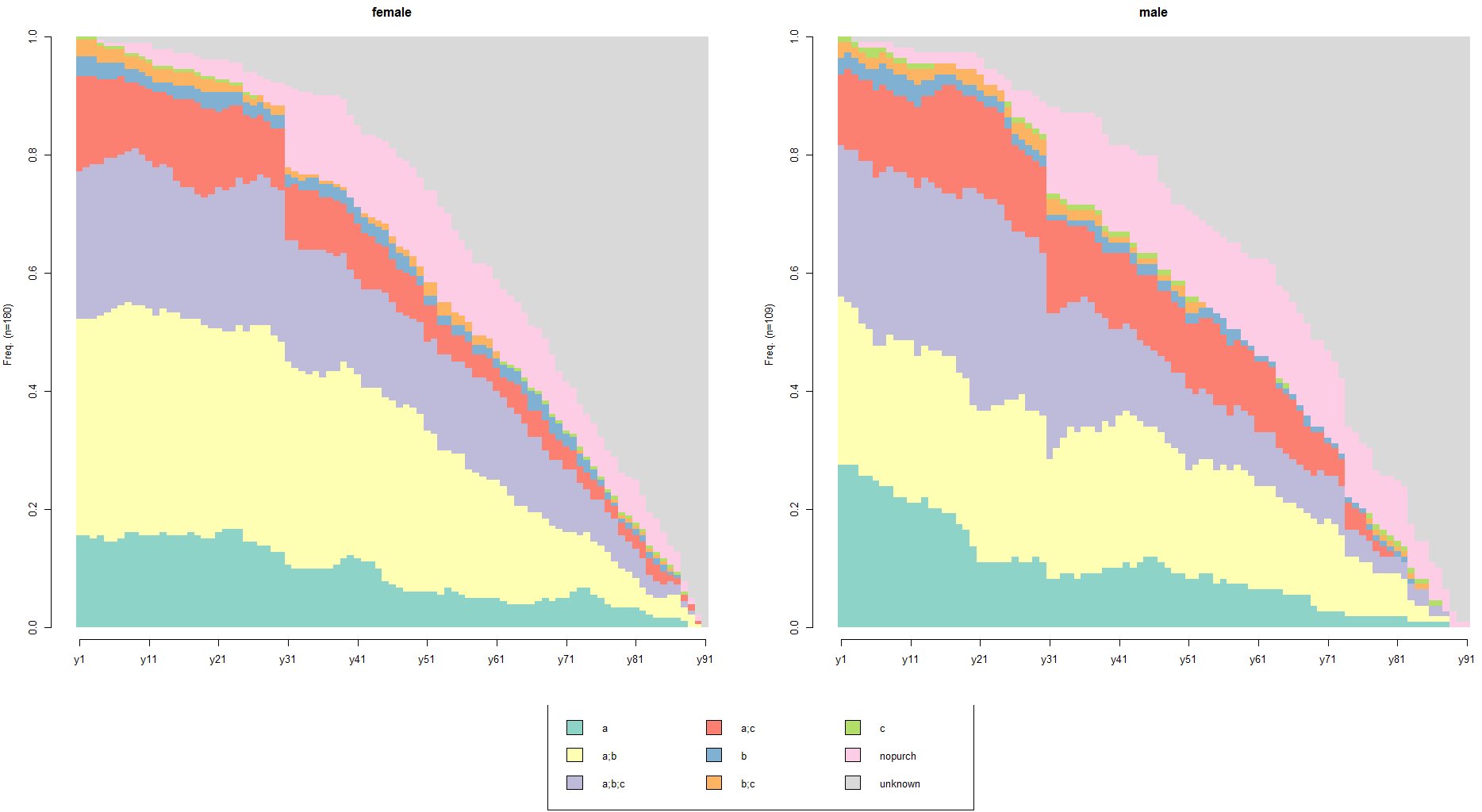
You can find some differences between the female’s and the male’s carts/orders distributions. For example, let’s take a look at (A;B) carts. Also, you can see an abrupt increase of ‘nopurch’ carts on the 31st day. This isn’t surprising because we used 30 days as the critical time lapse for one-time-buyers.
Furthermore, we can take a numeric data with the function:
seqstatd(df.seq)
In order to exclude the ‘unknown’ state from subsequent charts, we will reprocess our sequence object with the following code:
df.seq <- seqdef(df.form, left='DEL', right='DEL', xtstep=10)
We will analyse the most frequent sequences with the following charts and stats:
# the 10 most frequent sequences
seqfplot(df.seq, border=NA, withlegend='right')
# the 10 most frequent sequences based on gender
seqfplot(df.seq, group=df.feat$sex, border=NA)
# returning the frequency stats
seqtab(df.seq) # frequency table
seqtab(df.seq[, 1:30]) # frequency table for 1st month

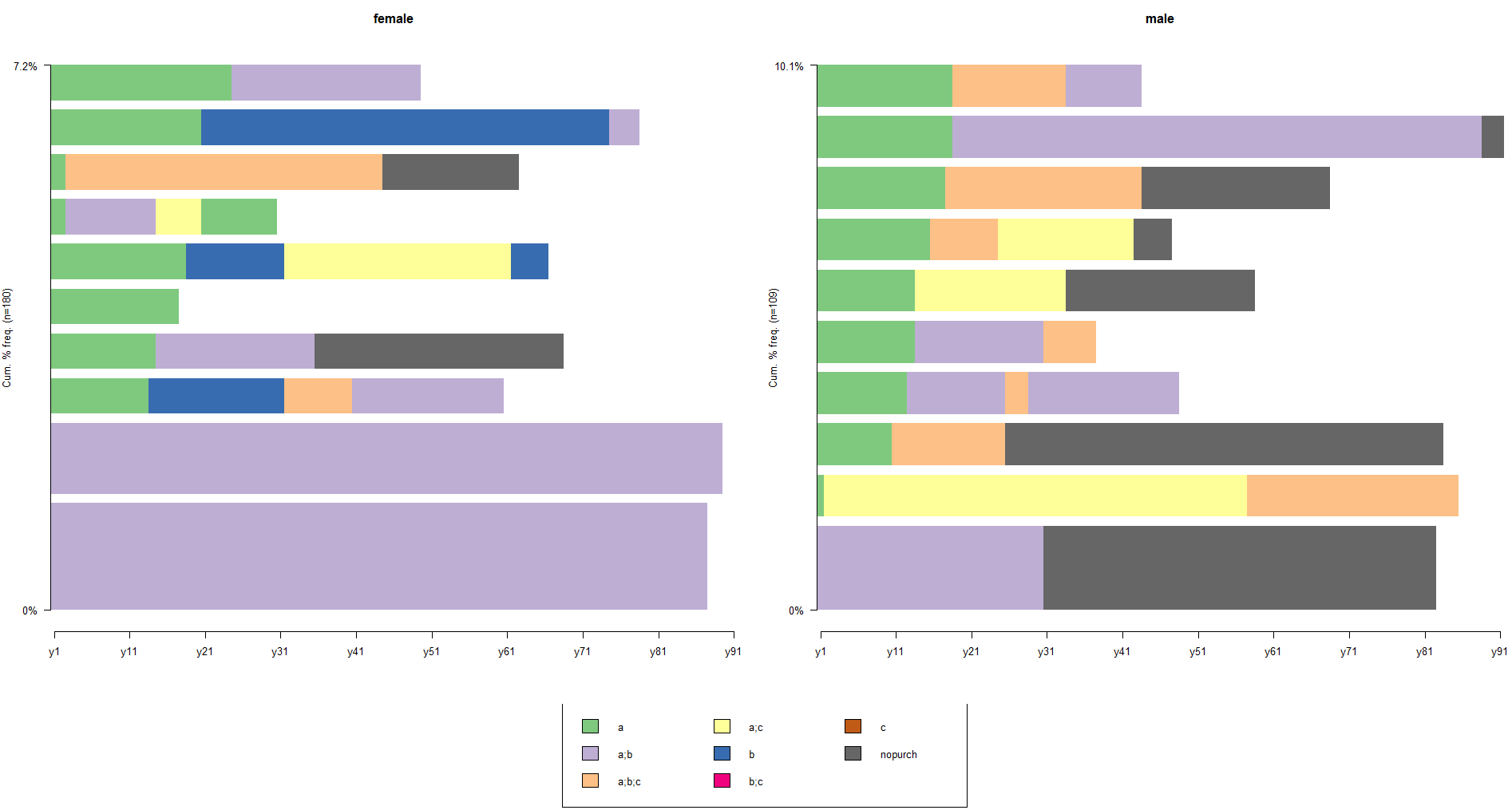
Each sequence is plotted as a horizontal bar split in as many colorized cells as there are states in the sequence. The sequences are ordered by decreasing frequency from bottom up and the bar widths are set proportionally to the sequence frequency. You can find, for instance, that male buyers didn’t purchase after the (A;B) carts while female buyers have long sequences of the same carts. Furthermore, we can see the most frequent sequences of shopping carts and exact day when states changed.
We will calculate the mean time spent on each state (with each cart/order) with the following code:
# mean time spent in each state
seqmtplot(df.seq, title='Mean time', withlegend='right')
seqmtplot(df.seq, group=df.feat$sex, title='Mean time')
statd <- seqistatd(df.seq) #function returns for each sequence the time spent in the different states
apply(statd, 2, mean) #We may be interested in the mean time spent in each state
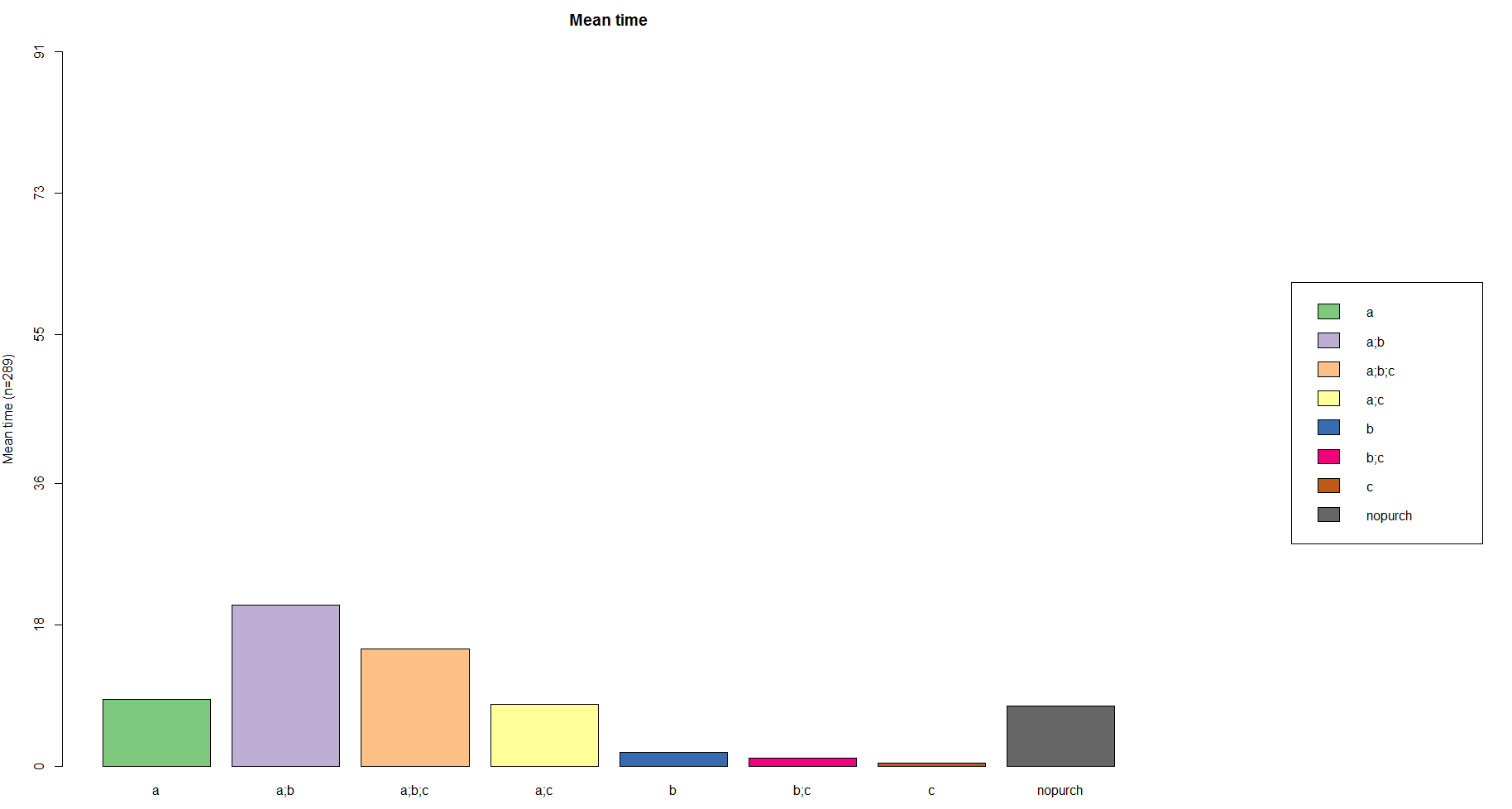
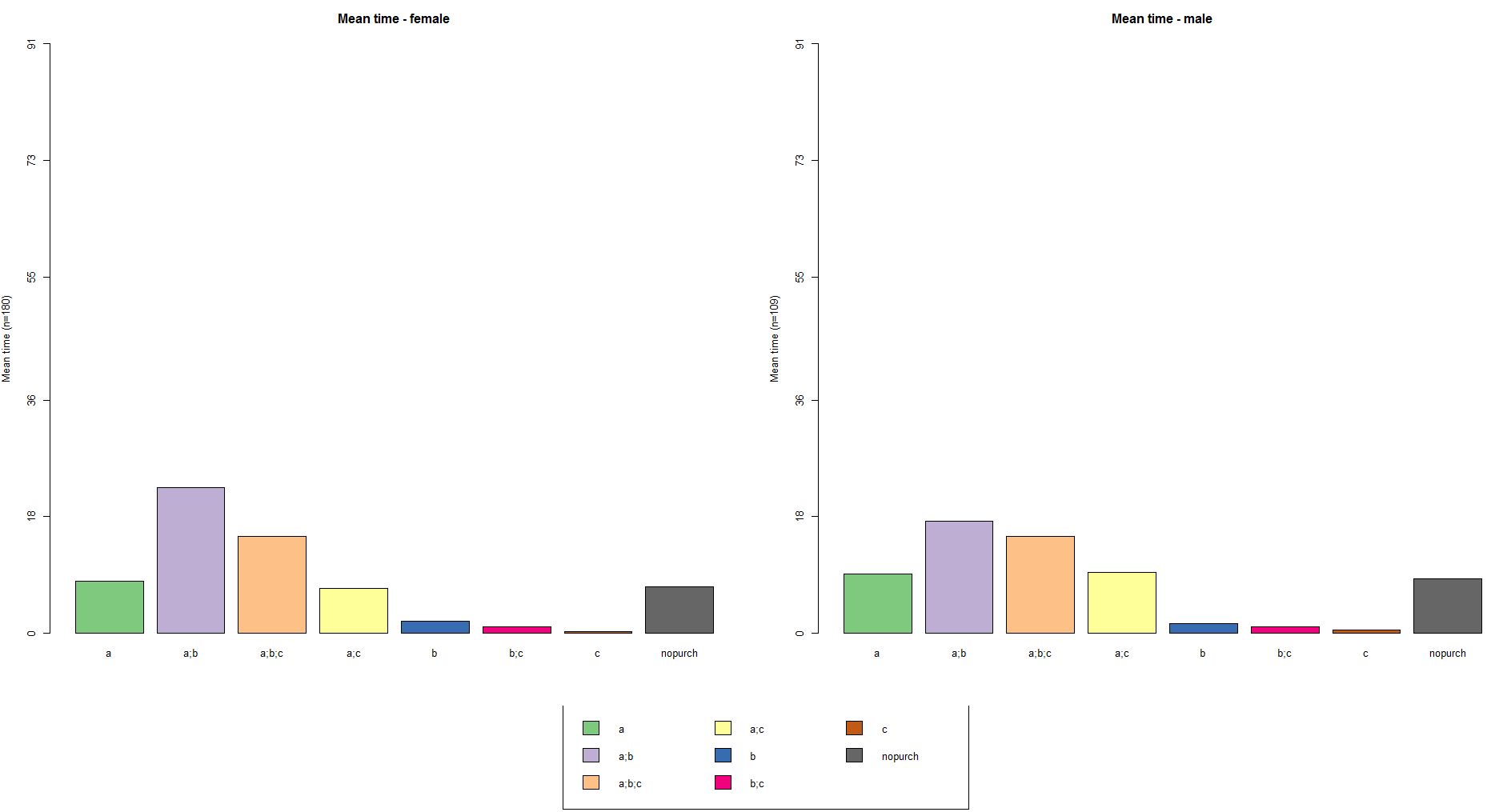
You can see that the average time on, for instance, (A;B) state is longer for female buyers, but (A) and (A;C) – for male one.
We will analyze entropy with the following code:
# calculating entropy
df.ient <- seqient(df.seq)
hist(df.ient, col='cyan', main=NULL, xlab='Entropy') # plot an histogram of the within entropy of the sequences
# entrophy distribution based on gender
df.ent <- cbind(df.seq, df.ient)
boxplot(Entropy ~ df.feat$sex, data=df.ent, xlab='Gender', ylab='Sequences entropy', col='cyan')

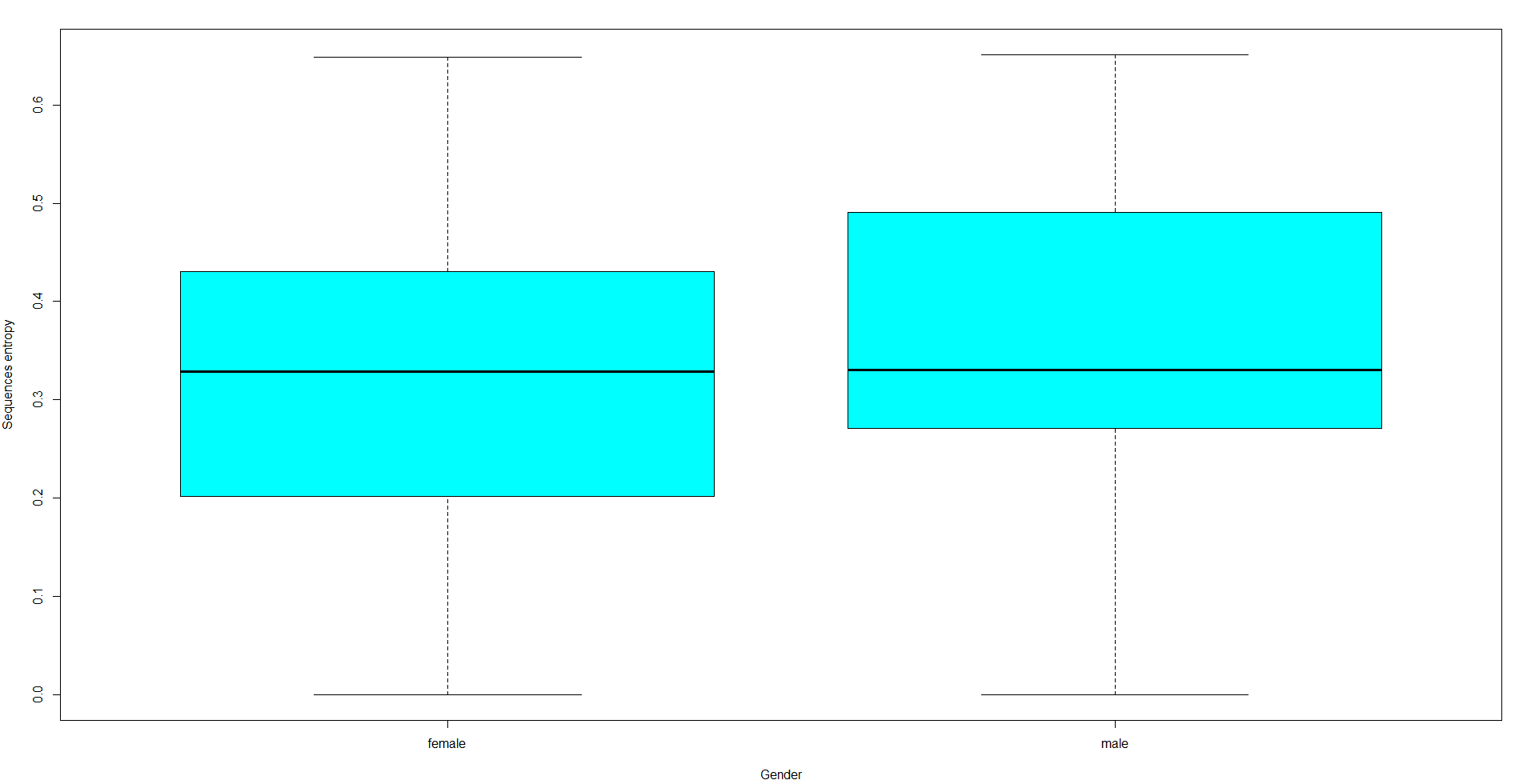
The chart shows that the entropy is slightly higher for the male clients when compared to the female ones.
I will cover clustering of clients based on their sequences in the next post. Don’t miss it if this interests you!
Author
